The CAR is pleased to announce the recent publication of the White Paper on De-Identification of Medical Imaging in the CARJ. Published in two parts – General Principles and Practical Considerations, the paper provides recommendations for CAR members and the Canadian radiology community to safely and efficiently maintain data privacy in the era of artificial intelligence (AI).
The new white papers join the series of AI white papers previously published by the CAR: an introductory white paper establishing Canada-specific standards and priorities, and a paper focused on ethical and legal considerations.
In Part 1, the author team, led by CAR members Dr. William Parker (UBC) and Dr. An Tang (Montreal) with co-senior author Prof. Rebecca Bromwich (Carleton), lay out the general, legal, and ethical principles associated with the management of patient data in Canada, with the intent to inform best practices in data management, access to healthcare data, de-identification, and accountability. Part 2 informs CAR members and the Canadian radiology community on the practical aspects of medical imaging de-identification, strengths and limitations of de-identification approaches, list of de-identification software and tools available, and perspectives on future directions with an emphasis on the Canadian clinical landscape.
As the authors observe, widespread use of patient data to train algorithms for clinical and research purposes,
“raises legal and ethical concerns about data privacy, balancing on the one hand beneficence and justice (improving medical care for others via secondary use of an individual’s data) versus autonomy, particularly regarding the concept of free and ongoing informed consent.”
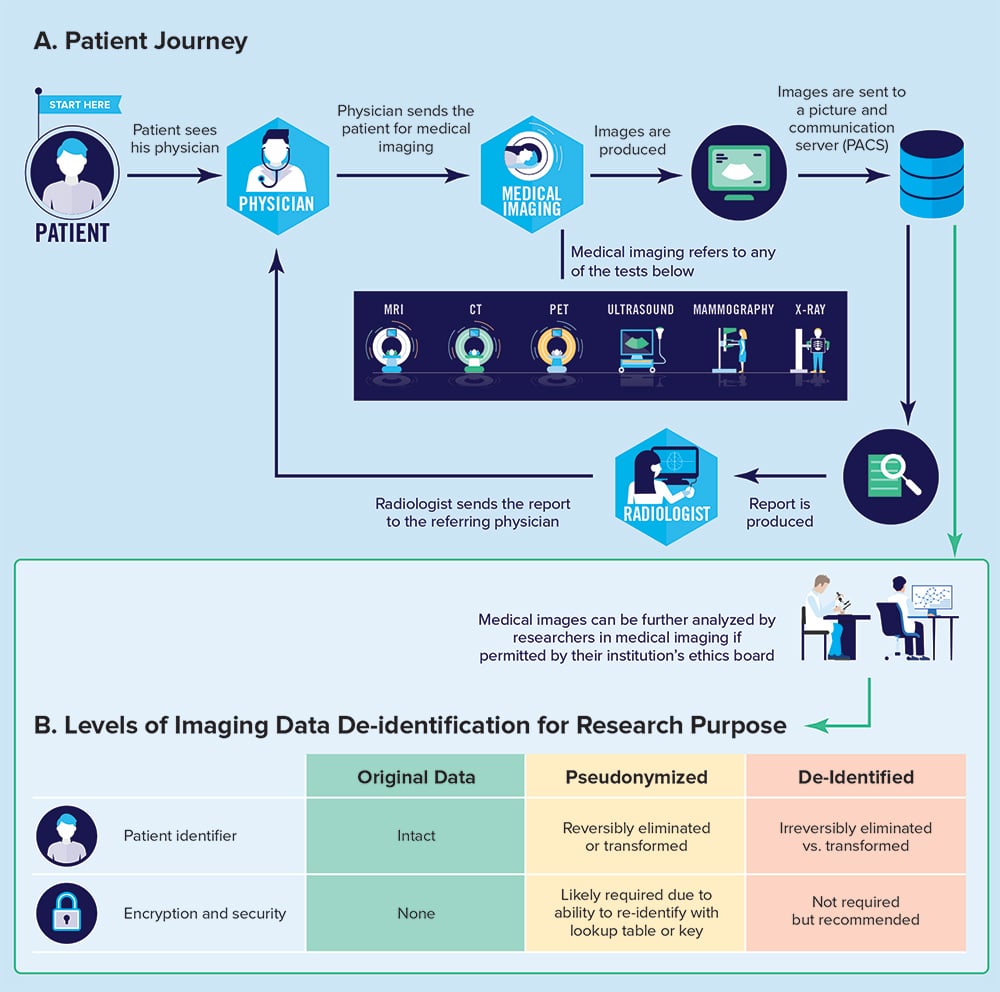
The medical images and report that are produced during the patient journey through a radiology department are data points that are useful for secondary purposes, such as research or quality assurance. However, the authors note,
“radiology image data are highly personal and sensitive. Images of a person may capture something of their essence, more than words, perhaps in some ways like data contained in an individual’s own genome, which can show what gene-related conditions that individual has or risks developing. Although medical image data are arguably not as identifiable as genome data, some of the ethical issues raised are broadly similar and can inform our deliberations.”
Ultimately, as clinicians and stewards of patient data, radiologists collaborating with scientists and software developers should be familiar with concepts of pseudonymization, de-identification, and encryption so that precautions can be taken to safeguard patient privacy. It is the hope of the CAR that the concepts and practical recommendations laid out in these white papers will serve to inform, inspire, and facilitate the work of Canadian radiologists in the ever-evolving AI landscape.
Summary of Recommendations
| Recommendation 1: Any custodian of patient data, such as a hospital, research facility, or health authority, needs to be comfortable with a small level of risk that an individual’s information in the data set can be potentially reidentified. The only way to achieve a zero risk of reidentification is not to make any data available. This ideal would inhibit advancement of research and our understanding of medicine and would prevent AI from being developed to improve patient care. |
| Recommendation 2: Public data set releases should be encouraged if the data can be de-identified to low reidentification risk. Public data sets promote openness, facilitate sharing, inspire national and international cohesiveness, and give groups in engineering and computer science the opportunity to work with data that would otherwise only be available to medical professionals. In the end, public data set releases facilitate more work on AI in health care, increasing the chances for lifesaving AI to assist more people around the world. |
| Recommendation 3: Medical AI algorithm validation is an important step prior to trusting these systems in any institution. Near identical security considerations should be made for AI validation as for AI model training. De-identification, data encryption, data release models, and data storage location are all important pieces to ensure patient data are kept safe. |
| Recommendation 4: Commercialization of AI adds another level of complexity to developing AI applications in health care. It is important when planning AI research projects to ensure ongoing access and funding to support long-term de-identified data access and secure storage when there is the possibility for regulatory approval and commercialization. |
| Recommendation 5: The creation of a reidentification competition where contestants are asked to hack into a medical data set using any tool available (including social media, publications, and photographs available online) to reidentify the individuals in the data set. This exercise would identify vulnerabilities in de-identification and encryption processes and provide valuable insight into how to improve upon these processes. |
| Recommendation 6: The process of medical data de-identification is a balance, much like the ALARA principle with respect to radiation dosages, “as little retained medical data as reasonably acceptable.” Retaining only the minimum DICOM header information, such as shown in Table 2 of this article, with additional considerations for technical parameters, optimizes the security and privacy of patient records by limiting the data being shared in a data set. |
| Recommendation 7: Using up-to-date data storage systems help to prevent a data breach, and using encryption helps protect confidentiality if a breach occurs. Research teams should carefully consider these when storing patient information, even if it is de-identified. |
| Recommendation 8: De-identification is a right, and not optional, even in case of emergency. Technology needs to support increased efficiencies for these scenarios rather than loosening standards. |