La CAR a le plaisir d’annoncer la publication de son White Paper on De-Identification of Medical Imaging dans le Journal de la CAR. Publié en deux parties (Principes généraux et Considérations pratiques, en anglais seulement), il fournit des recommandations aux membres de la CAR et à la communauté canadienne du domaine de la radiologie afin de préserver la confidentialité des données de façon sécuritaire et efficace à l’ère de l’intelligence artificielle (IA).
Cette nouvelle publication rejoint la série des livres blancs sur l’IA précédemment publiés par la CAR, soit un livre blanc d’introduction pour établir les normes et les priorités spécifiques au Canada et un article autour des considérations éthiques et juridiques.
Dans la première partie, l’équipe d’auteurs, menée par les Dr William Parker (UBC) et Dr An Tang (Montréal), membres de la CAR, ainsi que la coauteure principale Prof Rebecca Bromwich (Carleton), définit les principes généraux, juridiques et éthiques associés à la gestion des données des patients au Canada. L’objectif est de contribuer à l’élaboration de meilleures pratiques de gestion des données, d’accès aux données de soins de santé, d’anonymisation et de responsabilisation. La seconde partie a pour but d’informer les membres de la CAR et la communauté canadienne du domaine de la radiologie sur les aspects pratiques de l’anonymisation de l’imagerie médicale, les points forts et les limites des approches d’anonymisation, les logiciels et les outils d’anonymisation disponibles, ainsi que d’offrir des perspectives d’avenir en mettant l’accent sur le paysage clinique canadien.
Comme l’observent les auteurs, l’utilisation généralisée des données des patients pour entraîner les algorithmes à des fins cliniques et de recherche
« soulèvent des préoccupations d’ordre juridique et éthique concernant la protection des données, qui ont trait à l’équilibre entre, d’une part, les bienfaits qui en résultent et la justice sociale (amélioration des soins médicaux prodigués grâce à l’utilisation secondaire des données d’un patient) et, d’autre part, l’autonomie, tout particulièrement en ce qui concerne le concept de consentement libre, continu et éclairé ».
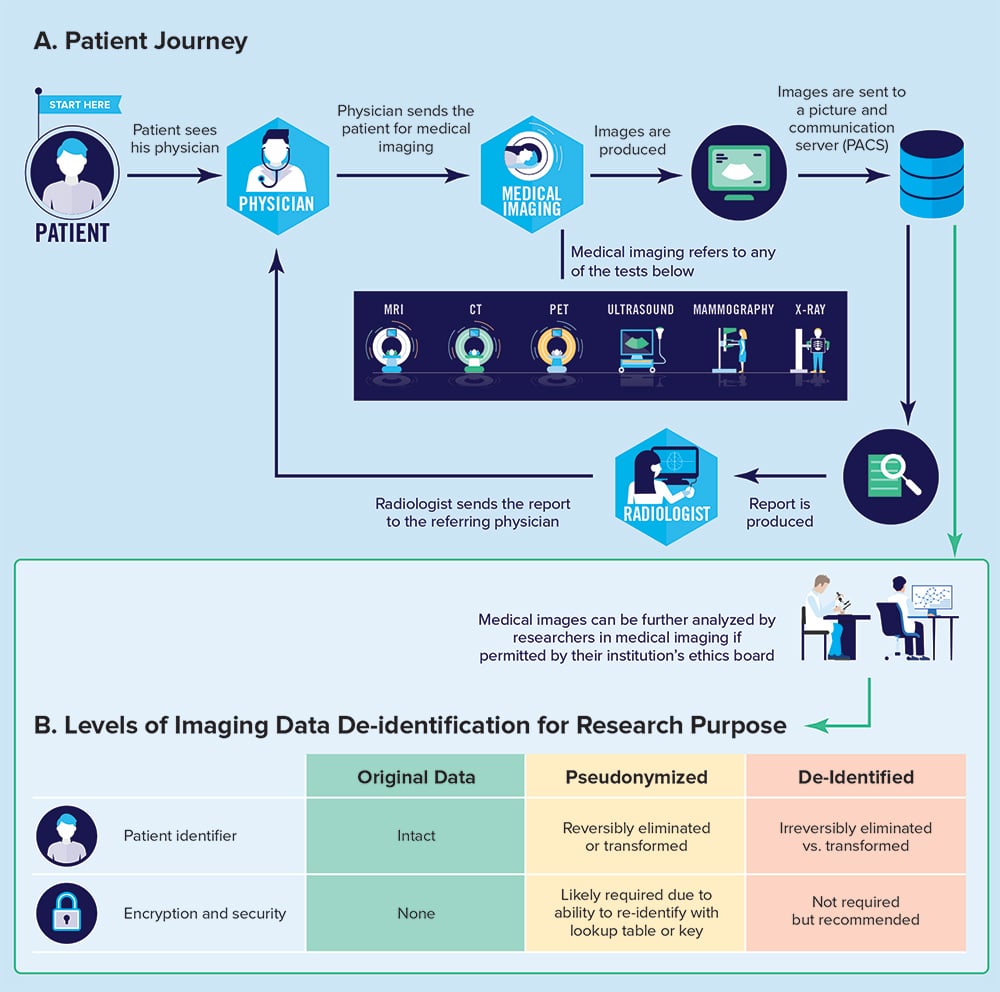
Les images médicales et les comptes-rendus produits lors du parcours d’un patient dans un service de radiologie sont des points de données utiles à des fins secondaires, notamment pour la recherche ou l’assurance de la qualité. Cependant, les auteurs constatent qu’
« en radiologie, les données d’imagerie sont très sensibles et personnelles. Plus que des mots, les images d’une personne peuvent saisir une partie de leur essence, peut-être en quelque sorte comme les données contenues dans le génome même d’un individu, qui peuvent dévoiler les maladies génétiques dont il souffre ou qu’il risque de développer. Même si les données d’imagerie médicale ne sont sans doute pas aussi identifiables que les données des génomes, certaines des préoccupations soulevées sont globalement comparables et peuvent éclairer notre réflexion. »
En tant que cliniciens et gardiens des données sur les patients, les radiologistes qui collaborent avec les scientifiques et les développeurs de logiciels devraient, à terme, bien connaître les concepts de pseudonymisation, d’anonymisation et de chiffrement afin de pouvoir prendre des précautions visant à protéger la confidentialité des patients. À la CAR, nous espérons que les concepts et les recommandations pratiques énoncés dans ces livres blancs serviront à influencer, inspirer et faciliter le travail des radiologistes canadiens dans un contexte où l’IA est en constante évolution.
Résumé des recommandations
| Recommandation no 1 : Toute personne ou structure conservant des données sur les patients, notamment les hôpitaux, les structures de recherche ou les autorités sanitaires, doit avoir conscience qu’il existe un faible risque de potentielle réidentification des renseignements sur un individu au sein de l’ensemble de données. La seule façon de parvenir au risque zéro de réidentification est de ne rendre aucune donnée disponible. Cet idéal entraverait les avancées de la recherche ainsi que notre compréhension de la médecine et empêcherait de développer l’IA à des fins d’amélioration des soins du patient. |
| Recommandation no 2 : La publication d’ensembles de données publiques devrait être encouragée dans les cas où les données peuvent être anonymisées de façon à présenter un faible risque de réidentification. Les ensembles de données publiques favorisent la transparence, facilitent le partage, encouragent une cohésion nationale et internationale et offrent aux groupes des domaines de l’ingénierie et de l’informatique la possibilité de travailler avec des données qui ne seraient autrement accessibles qu’aux professionnels de la santé. Enfin, les ensembles de données publiques facilitent les recherches sur l’IA dans les soins de santé, améliorant ainsi les probabilités que l’IA puisse sauver plus de vies dans le monde entier. |
| Recommandation no 3 : La validation des algorithmes des IA utilisées dans le domaine médical est une étape préliminaire importante si l’on veut ensuite pouvoir faire confiance à ces systèmes au sein d’une institution. Les considérations de sécurité doivent être quasiment les mêmes pour la validation de l’IA et pour le modèle d’entraînement de l’IA. L’anonymisation, le chiffrement, les modèles de communication et les lieux de stockage des données sont des éléments importants pour assurer la confidentialité des données sur les patients. |
| Recommandation no 4 : La commercialisation de solutions intégrant l’IA ajoute un niveau de complexité supplémentaire au développement des applications reposant sur l’IA dans le domaine des soins de santé. Lorsque l’on planifie un projet de recherche sur l’IA, il est important de garantir un accès et un financement continus afin de favoriser l’accès sur le long terme à des données anonymisées et à leur stockage sécurisé, dans les cas où l’approbation réglementaire et la commercialisation sont envisageables. |
| Recommandation no 5 : Il peut être utile d’organiser un concours de réidentification où les participant(e)s doivent pirater un ensemble de données médicales à l’aide de tous les outils à leur disposition (y compris les médias sociaux, les publications et les photographies disponibles en ligne) dans le but de réidentifier les individus de l’ensemble de données. Un tel exercice permettrait en effet de cerner les failles dans les traitements d’anonymisation et de chiffrement, mais aussi de fournir des renseignements précieux pouvant contribuer à les renforcer. |
| Recommandation no 6 : Le traitement de l’anonymisation des données médicales est une question d’équilibre. Tout comme le principe ALARA avec les doses de rayonnement, il faut « conserver aussi peu de données médicales qu’il est raisonnablement acceptable de le faire ». Conserver uniquement le minimum de renseignements avec l’en-tête DICOM, comme indiqué au Tableau 2 de cet article, et prendre davantage en compte les paramètres techniques permettent d’optimiser la sécurité et la confidentialité des dossiers des patients en limitant la diffusion de leurs données dans un ensemble de données. |
| Recommandation no 7 : L’utilisation de systèmes de stockage de données à jour contribue à éviter toute atteinte à la protection des données. L’utilisation du chiffrement permet de protéger la confidentialité en cas de brèche de données. Il est fortement conseillé aux équipes de recherche de prendre ces éléments en considération lorsqu’elles stockent des renseignements sur les patients, même anonymisés. |
| Recommandation no 8 : L’anonymisation est un droit. Elle n’est pas optionnelle, même en cas d’urgence. La technologie doit permettre une plus grande efficacité dans ces cas de figure, et non un assouplissement des normes. |